![Featured image of post [ElasticSearch]REST风格操作](/p/es_rest/restful_hud0b30a641456616a14ef2ef618957a76_22844_800x0_resize_box_3.png)
基本的rest命令
| method | url | 功能 |
|---|---|---|
| PUT | localhost:9200/索引名称/类型名称/文档id | 创建文档(指定文档id) |
| POST | localhost:9200/索引名称/类型名称 | 创建文档(随机文档id) |
| POST | localhost:9200/索引名称/类型名称/文档id/_update | 修改文档 |
| DELETE | localhost:9200/索引名称/类型名称/文档id | 删除文档 |
| GET | localhost:9200/索引名称/类型名称/文档id | 查询文档,通过文档id |
| POST | localhost:9200/索引名称/类型名称/_search | 查询所有数据 |
⚠️ 自定义类型将在以后的版本中弃用,规范起见一律使用
_doc类型
文档字段的数据类型
-
字符串类型
textkeyword -
数值类型
longintegershortbytedoublefloathalf floatscaled float -
日期类型
date -
布尔类型
boolean -
二进制类型
binary等等…..
基本操作
- 创建一个文档,如果索引不存在也会一起创建
PUT /test/_doc/1
{
"name":"ccqstark",
"age":3
}
没有指定字段的数据类型,es会默认配置
- 指定字段数据类型创建索引
PUT /test2
{
"mappings": {
"properties": {
"name":{
"type": "text"
},
"age":{
"type": "long"
},
"birthday":{
"type": "date"
}
}
}
}
- 基本查询
# 查询索引库信息
GET /{index}
# 查询具体某一文档
GET /{index}/_doc/{id}
- 查询es参数
GET _cat/[参数项]
- PUT更新
PUT /{index}/_doc/{id}
{
"name":"ccqstark666",
"age":3
}
直接在对应字段写上更新后的信息,会覆盖旧的值
如果漏了原来有的字段,那么这些字段会被删除,所以不推荐使用
- POST更新**(推荐)**
POST **/{index}/_update/{id}**
{
"doc":{
"name":"ccqstark555"
}
}
被修改的文档的"_version"会递增1
- 删除
# 删除索引库
DELETE /{index}
# 删除文档
DELETE /{index}/_doc/{id}
- 简单条件查询
GET /test/_doc/_search?q=name:ccqstark
⚠️ 如果字段类型是
keyword,说明不可分割,查询的时候分词器不会分割这个词来搜索,而是当成一个整体,而text类型可以被分词器解析
😮 查询出来的
"hits"里有"_score"是说明匹配度的分数值,匹配度越高,分数越高
复杂(花式)搜索
match查询
GET /test/_doc/_search
{
"query":{
"match":{
"name":"ccqstark"
}
}
}
match不是精确搜索,会使用分词器解析再搜索(默认自带分词器把英文按空格分词,中文是每一个字都分开)
使用json构建查询参数体
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
}
查询结果中的 hits里有个total的value,为查询结果的总数量
- 过滤查询结果的字段
GET /test/_doc/_search
{
"query":{
"match":{
"name":"ccqstark"
}
},
"_source":["name","age"]
}
"_source" 可以用来指定查询结果中的字段,相当于select xxx,xxx
- 结果排序
GET /test/_doc/_search
{
"query":{
"match":{
"name":"ccqstark"
}
},
"sort":{
"age":{
"order":"desc"
}
}
}
这里 "sort" 指定age为用来排序的字段,"order" 为排序方式
升序:asc
降序:desc
- 分页查询
GET /test/_doc/_search
{
"query":{
"match":{
"name":"ccqstark"
}
},
"from":0,
"size":2
}
“from”是从第几页开始,第一页为0
“size”是每页多少条数据
bool查询
GET /test/_doc/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "ccqstark"
}
},
{
"match": {
"age": 100
}
}
]
}
}
}
用bool可以实现多条件查询
这里的must相当于and,也就是所有条件都要符合
也可以用should ,相当于or
还有must_not ,相当于not
bool嵌套
GET /my_store/products/_search
{
"query" : {
"filtered" : {
"filter" : {
"bool" : {
"should" : [
{ "term" : {"productID" : "KDKE-B-9947-#kL5"}},
{ "bool" : {
"must" : [
{ "term" : {"productID" : "JODL-X-1937-#pV7"}},
{ "term" : {"price" : 30}}
]
}}
]
}
}
}
}
}
bool查询里再套一个bool,就相当于加了个括号:( A or ( B and C ))
filter查询
GET /test/_doc/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"name": "陈楚权"
}
}
],
"filter": {
"range": {
"age": {
"gte": 66,
"lte": 100
}
}
}
}
}
}
range 表示范围查询,age 指定了字段
范围查询表达式
| 表达式 | 表示 |
|---|---|
| gt | > |
| gte | >= |
| lt | < |
| lte | <= |
- 多关键词查询
GET /test/_doc/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "ccq java"
}
}
]
}
}
}
用空格隔开关键词就行
term精确查询
GET /test3/_doc/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"name": "ccq说java"
}
}
]
}
}
}
⚠️ 使用
term查询要求字段为keyword类型才能匹配出来
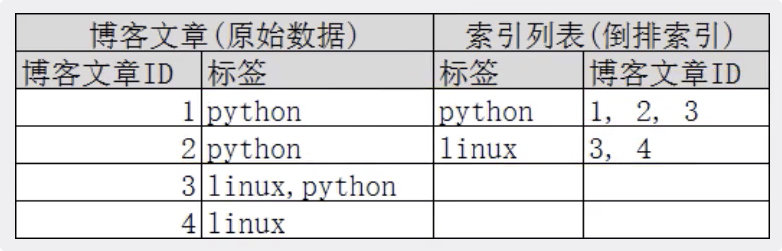
term是精确查询,于match会用分词器解析不同,term是直接通过倒排索引指定的词条进行精确查找
- 高亮查询
GET /test/_doc/_search
{
"query": {
"match": {
"name": "java"
}
},
"highlight": {
"fields": {
"name": {}
}
}
}
返回值中的highlight字段里会有带高亮标签的搜索结果,默认标签为<em>,效果如下
{
"_index" : "test",
"_type" : "_doc",
"_id" : "6",
"_score" : 1.1631508,
"_source" : {
"name" : "ccq说java",
"age" : 100
},
"highlight" : {
"name" : [
"ccq说<em>java</em>"
]
}
}
高亮标签可以自定义,用前标签pre_tags和后标签post_tags 来指定
GET /test/_doc/_search
{
"query": {
"match": {
"name": "java"
}
},
"highlight": {
"pre_tags": "<p class='key' style='color:red'>",
"post_tags": "</p>",
"fields": {
"name": {}
}
}
}
参考自狂神的ElasticSearch教程:
【狂神说Java】ElasticSearch7.6.x最新完整教程通俗易懂