![Featured image of post [ElasticSearch]ElasticSearch入门与原理浅析](/p/es_principle/es_hu709c9dbb1dd93df65cfe69a9e6744979_88514_800x0_resize_box_3.png)
简介
引入
对于搜索功能,大家以前都是怎么做的呢?我相信很多人一开始也是用SQL的LIKE关键字加上%来匹配关键字的吧,为了实现更好的模糊效果就再加一个分词器来拆分关键词。但是,一旦被搜索的数据量一大,这种方式就显得效率低下。为了实现更好的效果,我们可以使用当前最流行的分布式搜索引擎——ElasticSearch 。
基本介绍
Elasticsearch 是一个分布式的免费开源搜索和分析引擎,适用于包括文本、数字、地理空间、结构化和非结构化数据等在内的所有类型的数据,基于著名的Lucene库进行开发,并以简单的RESTful风格的API进行调用,支持Java、JavaScript(Node)、Go、 C#(.NET)、PHP、Python、Ruby等多种语言。ElasticSearch已经成为非常流行的搜索引擎,一些著名厂商例如京东、滴滴、携程、Stack Overflow、GitHub等都在使用。
官网地址:https://www.elastic.co/cn/elasticsearch/

应用场景
- 应用程序搜索
- 网站搜索
- 企业搜索
- 日志处理和分析
- 基础设施指标和容器监测
- 应用程序性能监测
- 地理空间数据分析和可视化
- 安全分析
- 业务分析
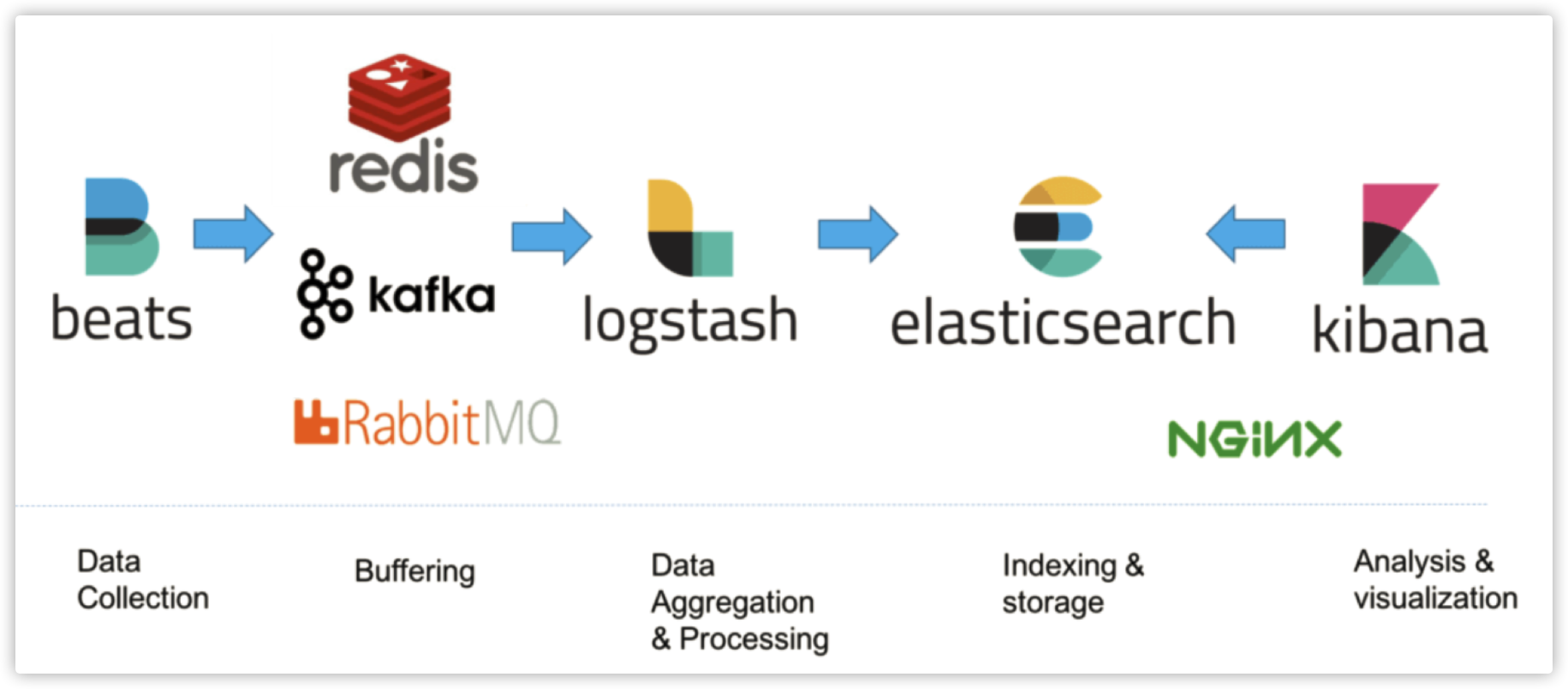
ELK
ELK,即ElasticSearch + logstash + Kibana ,是一套开源的日志收集与分析解决方案。利用ElasticSearch对数据进行快速的复杂条件检索,用logstash则作为数据管道从多个来源进行数据的采集、转换和传输,Kibana则通过生成多种可视化报表方便用户进行日志监控。
一般小型系统我们分析日志可以直接在用grep、awk等命令进行过滤与检索,或者拉到本地用LogViewer等专门的日志工具打开查看。但是当系统体量一大,采用的是分布式架构,集群中的日志管理就成为一个难题。ELK目的就是为了解决大型系统中的日志收集、存储与分析问题,方便将节点中的日志统一管理从而提高效率。
概念介绍
基本概念
ElasticSearch(简称es)搜索的时候不是去数据库里拿数据,它有自己的一套存储与索引体系。数据库中的数据需要同步到es中,通过索引的形式来存储数据才能实现高效检索。
es索引体系的基本概念和关系型数据库中的有些类似,我们可以对比着来看
| Index 索引 | Database 数据库 |
|---|---|
| Type 文档类型 | Table 表 |
| Document 文档 | Row 记录 |
| Field 字段 | Column 属性 |
| Mapping 映射 | Schema 模型 |
| Query DSL | SQL |
es的层次组织结构类似于MySQL这样的关系型数据库,index就像database那样存储着不同的type,也就是数据库中的table;再下一级就是document,类似于数据库中的一条条记录;每条记录的字段field就对应表中的column;mapping就如schema那样表示着库表的架构;es中的查询语言Query DSL则对标我们熟悉的SQL。通过类比可以更快地认识es的结构组成。
⚠️ 注意:从6.x开始es慢慢放弃type,并统一默认type为_doc,预计在8.x正式将其移除。
其它概念
-
Node节点实际项目中我们往往不会只用一台服务器来部署elasticsearch,那样的话能够承载的用户数就非常少。因为es是一个分布式的搜索引擎,那我们完全可以部署一个es集群,而其中的一个服务器实例就叫做node(节点)。
-
Cluster集群一个cluster是有多个node组成的,es集群可以扩大单个节点的数据存储量以及承载的搜索请求。在其中一个节点挂掉的情况下不影响其他节点的正常工作。es集群也可以设置或选举master node来负责创建索引、删除索引、分配分片、追踪集群中的节点状态等,当然也可能存在脑裂问题。其它普通节点称为data node,用来接受用户的搜索请求返回搜索结果。
-
Shard分片上面说到集群可以扩大单机存储空间过小的问题,而其中实现的原理就是通过分片。es通过对数据进行水平拆分成多个部分,然后分发到多台物理机上,这个过程叫做索引分片(Sharding),每个部分就是一个分片(Shard)。创建索引时可以指定分片数量,一旦指定就不可更改。sharding的过程是es自动完成的,数据被写入时会被指定写入的分片。es的分片是Lucene实现的。
-
Replica索引副本索引副本就是对分片进行的拷贝。在某一分片请求负载导致阻塞时,replica同样可以处理用户的请求。而且不仅可以提高流量承载能力,同时数据也有了一份备份,即使主分片数据丢掉也可以用副本恢复。
安装与基本使用
容器部署
云原生时代推荐使用容器,这里以docker单机部署为例简单讲下。
# 拉取镜像,这里是7.10.1,注意es版本间兼容性较差
docker pull elasticsearch:7.10.1
# 启动容器,配置文件和数据挂载出来
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e ES_JAVA_OPTS="-Xms256m -Xmx256m" -d \
-v [主机挂载目录]/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v [主机挂载目录]/data:/usr/share/elasticsearch/data elasticsearch:7.10.1
es容器是比较占内存的,毕竟一开就是一个JVM,单节点内存较小可以通过设置ES_JAVA_OPTS 来调小JVM的内存占用,例如上面例子中都参数就是设置为256M。
其他可能出现的问题以及更多相关组件安装如Kibana或ik分词器可以参看我的另一篇博客,这里不再赘述。
[Elastic]使用docker安装ElasticSearch + Kibana
RESTful风格操作
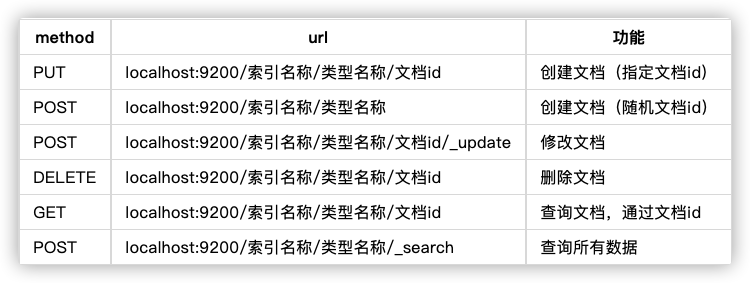
es使用RESTful风格的API进行CRUD,存储与传输使用的数据形式也是使用常见的JSON,常用的method和对应的功能如下:
客户端
es提供了多种语言的client,各种API文档都在官网可以找到。对于Java推荐使用Java High Level REST Client,与SpringBoot的整合可以看我另一篇博客。
官方文档地址:https://www.elastic.co/guide/en/elasticsearch/client/index.html
MySQL的LIKE探究
索引使用
我们习惯用LIKE进行模糊查询,但是当数据量很大时耗时就会比较久,也许你会想到用索引来实现优化,但是模糊查询使用索引是要满足一定条件的。
单%模糊,且查询字段加了索引- 使用
双%进行全模糊查询,且把主键作为结果集,因为覆盖索引所以查询会走索引 - 使用全文索引
为了探究在大量数据情况下LIKE+%方案的效果,下面用个例子来实践一下。
数据准备
建一张简单的表供查询,引擎是InnoDB
CREATE TABLE `test_like` (
`id` int(11) UNSIGNED NOT NULL AUTO_INCREMENT,
`name` varchar(20) NOT NULL DEFAULT '',
`student_number` varchar(11) NOT NULL DEFAULT '',
PRIMARY KEY (`id`)
);
准备多点数据,这里我准备了10万条。
注意这里一次性插入太多数据可能会出现PacketTooBigException,可以分批插入或者设置max_allowed_packet
<insert id="insertLikeTestData">
insert into test_like
(`name`,`student_number`) VALUES
<foreach collection="list" item="item" index="index" separator=",">
('ccq','50377880000'+#{item})
</foreach>
</insert>
然后给我们用来查询的student_number加个索引
ALTER TABLE `test_like`
ADD INDEX `idx_student_number`(`student_number`) USING BTREE;
查看执行计划
首先我们执行select * 的全模糊查询
explain select * from test_like where student_number like '%503%'\G
发现并没有使用索引并进行了全表扫描
id: 1
select_type: SIMPLE
table: test_like
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 100076
filtered: 11.11
Extra: Using where
1 row in set, 1 warning (0.00 sec)
然后我们执行select id 的单%查询,也就是将主键作为结果集
explain select id from test_like where student_number like '503%'\G
发现的确使用了索引进行了优化,扫描行数只有一半
id: 1
select_type: SIMPLE
table: test_like
partitions: NULL
type: range
possible_keys: idx_student_number
key: idx_student_number
key_len: 46
ref: NULL
rows: 50038
filtered: 100.00
Extra: Using where; Using index
1 row in set, 1 warning (0.00 sec)
最后我们select id 的双%查询
explain select id from test_like where student_number like '%503%'\G
这个时候我们发现确实使用我们创建的idx_student_number ,但是possible_keys居然是NULL
而且还发现,使用索引与不使用索引,扫描行数都是一样的,而且都是全表扫描
id: 1
select_type: SIMPLE
table: test_like
partitions: NULL
type: index
possible_keys: NULL
key: idx_student_number
key_len: 46
ref: NULL
rows: 100076
filtered: 11.11
Extra: Using where; Using index
1 row in set, 1 warning (0.00 sec)
使用Trace查看优化器
我们跟踪一下MySQL的优化器是怎么做选择的
-- 开启优化器跟踪
set session optimizer_trace='enabled=on';
select * from test_like where student_number like '%503%';
-- 查看优化器追踪内容
select * from information_schema.optimizer_trace;
找到查询路径的选择
"best_access_path": {
"considered_access_paths": [
{
"rows_to_scan": 100076,
"access_type": "scan",
"resulting_rows": 100076,
"cost": 20304,
"chosen": true
}
]
}
然后对选择主键的双%查询也进行同样的跟踪,发现两者同样都是用了顺序扫描,而没有用上B+Tree来优化。
结论
从上面我们也可以看到,没有做其它的优化而只用索引来使用MySQL的LIKE进行全模糊查询,在数据量大的时候,性能还是不尽人意的,这也说明了使用ES的必要性。
索引原理
这一部分我们来说说ES的一些原理,看看为什么ES在查询上能更胜MySQL一筹。
倒排索引
es是通过Lucene的倒排索引Inverted Index技术来实现比普通关系型数据库更快的查询的,特别对多条件的复杂查询,这一点能更好地体现。
那什么是倒排索引呢?引用维基上的定义:
倒排索引是一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。它是文档检索系统中最常用的数据结构。
有两种不同的反向索引形式:
- 一条记录的水平反向索引(或者反向档案索引)包含每个引用单词的文档的列表。
- 一个单词的水平反向索引(或者完全反向索引)又包含每个单词在一个文档中的位置。
其实很好理解,就是把我们以前设计表的那种把文章对应里面有哪些单词的结构,倒过来,变成一个单词与被包含在哪些文章中的对应关系,当我们搜索一个单词的时候就能快速得到包含这个单词的文章列表来。
举个例子:
比方说下面这张表

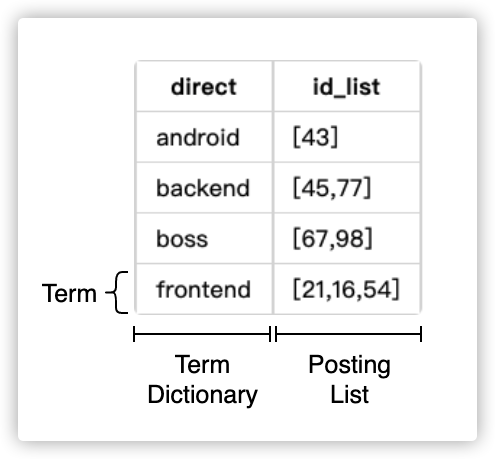
对于上面的倒排表,我们把其中每一项称为Term,被索引的那一列也就是实例的direct字段为Term Dictionary ,对应被检索出来的id_list字段为Posting List。
被检索的direct如果按顺序排列的话就可以用二分搜索快速找出,或者也可以在其上再加一层BTree来索引,提高关键词本身的搜索速度。
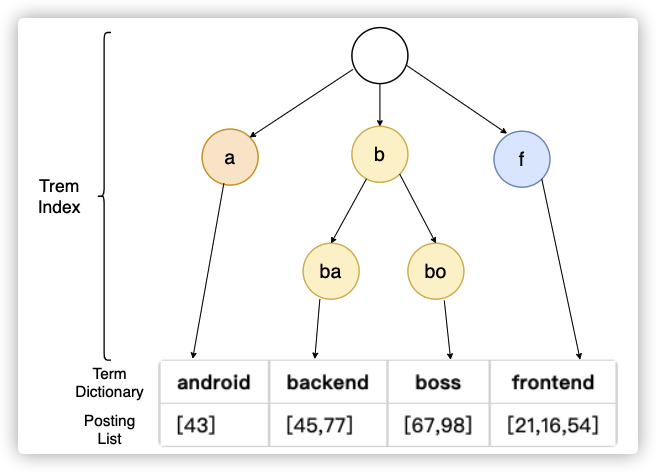
Term Index
当数据量很大的时候,Term Dictionary也会变得很大,无法完全放入内存(es本身运行已经占用非常大的内存了),这个时候我们再加一层索引叫Term Index。
es使用 Burst-Trie 结构来实现,它是字典树(前缀树)Trie 的一种变种,它主要是将后缀进行了压缩,降低了Trie的高度,从而获取更好查询性能。
联合查询合并
当我们用es进行联合查询时,比如查找方向为backend且年份等于2019的人,我们只需要对direct和year字段分别用倒排索引查找出结果集,最后对结果集进行合并就行了。
在关系型数据库中我们一般会用join来合并两表,这里再次鞭尸一下MySQL,它的join实现性能也很差。比如下面这样的SQL:
select * from t2 straight_join t1 on (t2.a=t1.a);
straight_join 保证优化器不改变驱动表,用Index Nested-Loop Join 算法执行流程如下:
- 从 t2 表中读取一行数据 L2
- 使用L2的 a 字段,去 t1 表中作为条件进行查询
- 取出 t1 中满足条件的行, 跟 L2组成相应的行,成为结果集的一部分
- 重复执行,直到扫描完 t2 表
所以阿里开发者规范禁止三张表以上的 join 操作,是有原因滴。
而Elasticsearch使用跳表Skip List和位图Bitset来合并结果集,下面介绍一下这两种方法。
Skip List合并策略
说到跳表,我们首先讲一下普通的链表,如下图:

然后说跳表Skip List,实际上是在链表的基础上多加了几层索引,使得查询效率加快,如图:
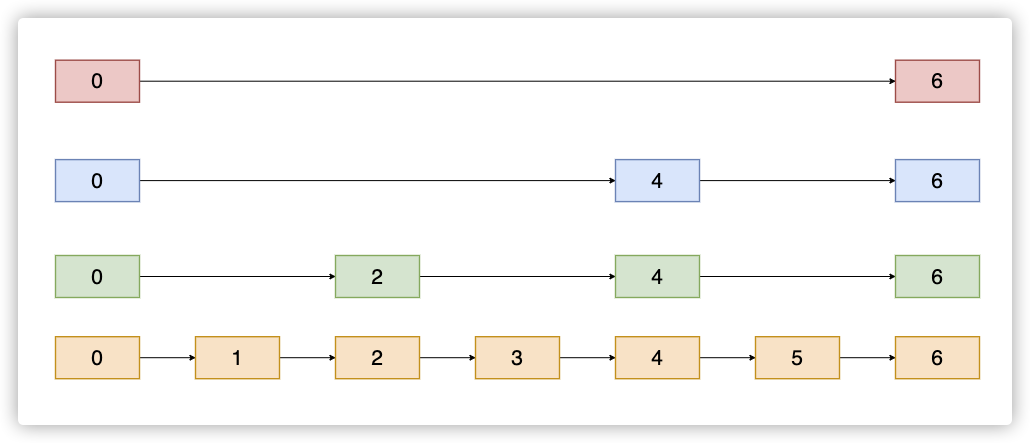
ES利用Skip List进行合并结果集的时候就是从上往下,找到节点值大于等于目标值的最小节点,如果还是大于目标值,那就往下一层,相当于增加查找精度。例如我现在要找的目标值为2,从最上一层开始找,这层是0—>6,6明显大于2了,到下一层;这一层是0—>4—>6,找到4还是大于2,那继续下一层;这时是0—>2—>4—>6,我们就可以找到目标值2了。
利用跳表,ES在找两个结果集的交集的时候就会快很多。
Roaring Bitset合并策略
除了用Skip List来加快合并之外,ES还会把不同条件查询的结果集Posting List放到内存中缓存。如果直接用普通的数据结构,比如数组这样的,就其实很消耗空间;如果用Bitset,可能会有过于稀疏而导致的空间浪费。所以ES采用压缩效率更高的Roaring Bitmap来存储。
这里插播一道面试题:给定含有40亿个不重复的位于[0, 2^32 - 1]区间内的整数的集合,如何快速判定某个数是否在该集合内?
如果我们要使用 unsigned long 数组来存储它的话,也就需要消耗 40亿 * 32 位 =160亿Byte,大约是 16000 MB。 如果使用位图 Bitset 来存储的话,即某个数如果存在的话,就将它对应的位图内的比特置为1,否则保持为0。这样多少个树就只需要消耗多少bit来存,这里是 2 ^ 32 位 = 512 MB,这可只有原来的 3.2 % 左右。
Roaring Bitmap又是如何来解决稀疏的问题的呢?直接上图:
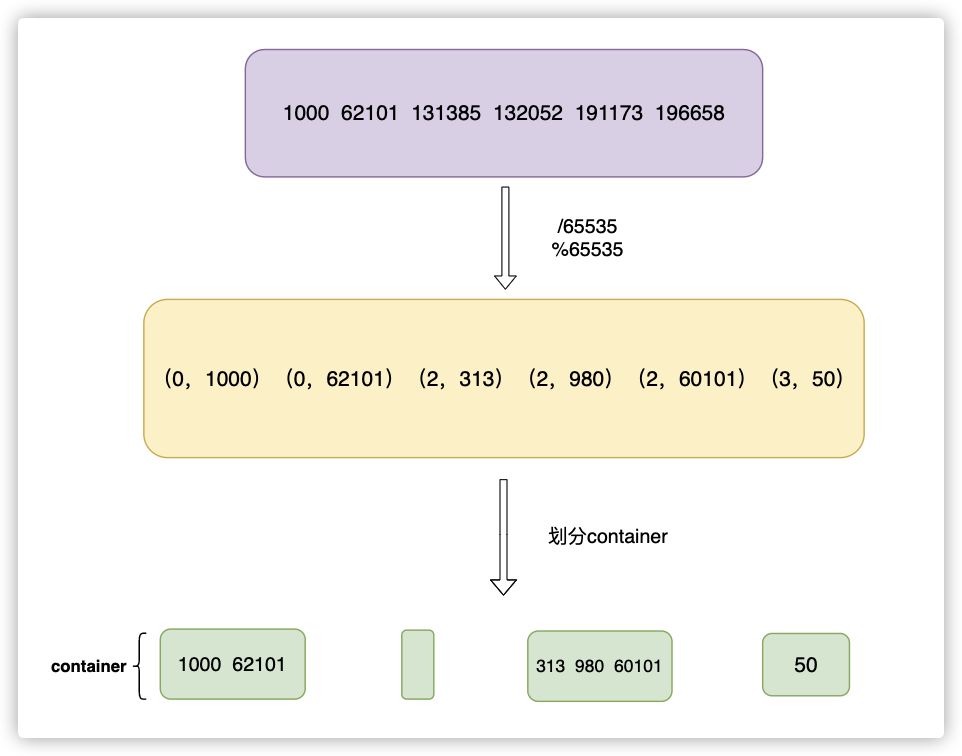
container,最后只需要存各container中的余数即可。
所以RoaringBitmap其实就是很多container的集合,如果是一个32位unsigned long的话,那最多就有2^32 / 65535 = 65535个container。
对于其中的余数的存储(低16位),则是以下的存储规则:
- 余数小于 2 ^ 12 次方(4096)时,使用unsigned short类型的有序数组来存储,最大消耗空间为 8 KB。
- 余数大于 4096 时,则使用大小为 2 ^ 16 次方的普通 bitset 来存储,固定消耗 8 KB。有些时候也会对 bitset 进行run-length encoding压缩,进一步缩小占用内存。
ES利用Roaring Bitset缓存不同条件查出来的Posting List,最后通过与操作合并出最终结果集。
小结
- ElasticSearch是一个分布式开源搜索引擎,支持多种语言客户端,拥有丰富的应用场景,受到许多企业的青睐。
- ElasticSearch方便部署集群,使用RESTful风格等API进行调用。
- MySQL的LIKE字句只在特定情况下才使用索引,且性能不高,无法应对大数据亮搜索任务。
- ElasticSearch使用倒排索引与Term Index来提高搜索效率,减少磁盘I/O。
- ElasticSearch使用Skip List和Roaring Bitset来合并复杂条件查询的结果集。